Basics
Introduction
DBMS stands for Database Management System. We can break it like this DBMS = Database + Management System. Database is a collection of data and Management System is a set of programs to store and retrieve those data. Based on this we can define DBMS like this: DBMS is a collection of inter-related data and set of programs to store & access those data in an easy and effective manner.
Advantages of DBMS over file system
Drawbacks of File system
- Data redundancy: Data redundancy refers to the duplication of data, lets say we are managing the data of a college where a student is enrolled for two courses, the same student details in such case will be stored twice, which will take more storage than needed. Data redundancy often leads to higher storage costs and poor access time.
- Data inconsistency: Data redundancy leads to data inconsistency, lets take the same example that we have taken above, a student is enrolled for two courses and we have student address stored twice, now lets say student requests to change his address, if the address is changed at one place and not on all the records then this can lead to data inconsistency.
- Data Isolation: Because data are scattered in various files, and files may be in different formats, writing new application programs to retrieve the appropriate data is difficult.
- Dependency on application programs: Changing files would lead to change in application programs.
- Atomicity issues: Atomicity of a transaction refers to “All or nothing”, which means either all the operations in a transaction executes or none.For example: Lets say Steve transfers 100$ to Negan’s account. This transaction consists multiple operations such as debit 100$ from Steve’s account, credit 100$ to Negan’s account. Like any other device, a computer system can fail lets say it fails after first operation then in that case Steve’s account would have been debited by 100$ but the amount was not credited to Negan’s account, in such case the rollback of operation should occur to maintain the atomicity of transaction. It is difficult to achieve atomicity in file processing systems.
- Data Security: Data should be secured from unauthorised access, for example a student in a college should not be able to see the payroll details of the teachers, such kind of security constraints are difficult to apply in file processing systems.
Advantage of DBMS over file system
There are several advantages of Database management system over file system. Few of them are as follows:
- No redundant data: Redundancy removed by data normalization. No data duplication saves storage and improves access time.
- Data Consistency and Integrity: As we discussed earlier the root cause of data inconsistency is data redundancy, since data normalization takes care of the data redundancy, data inconsistency also been taken care of as part of it
- Data Security: It is easier to apply access constraints in database systems so that only authorized user is able to access the data. Each user has a different set of access thus data is secured from the issues such as identity theft, data leaks and misuse of data.
- Privacy: Limited access means privacy of data.
- Easy access to data – Database systems manages data in such a way so that the data is easily accessible with fast response times.
- Easy recovery: Since database systems keeps the backup of data, it is easier to do a full recovery of data in case of a failure.
- Flexible: Database systems are more flexible than file processing systems.
View of Data in DBMS
Abstraction is one of the main features of database systems. Hiding irrelevant details from user and providing abstract view of data to users, helps in easy and efficient user-database interaction. In the previous tutorial, we discussed the three level of DBMS architecture, The top level of that architecture is “view level”. The view level provides the “view of data” to the users and hides the irrelevant details such as data relationship, database schema, constraints, security etc from the user.
To fully understand the view of data, you must have a basic knowledge of data abstraction and instance & schema. Refer these two tutorials to learn them in detail.
- Data abstraction
- Instance and schema
1. Data Abstraction in DBMS
Database systems are made-up of complex data structures. To ease the user interaction with database, the developers hide internal irrelevant details from users. This process of hiding irrelevant details from user is called data abstraction.
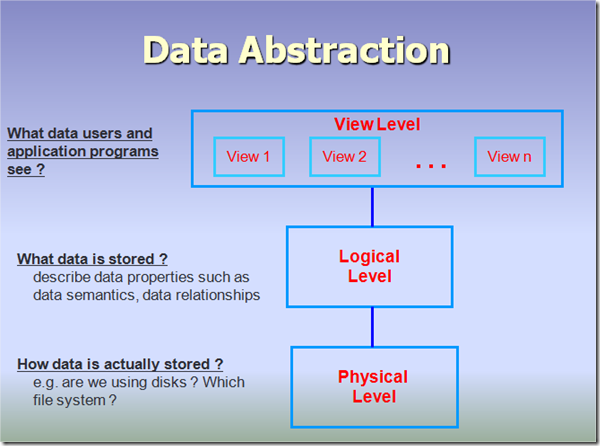
We have three levels of abstraction:
Physical level: This is the lowest level of data abstraction. It describes how data is actually stored in database. You can get the complex data structure details at this level.
Logical level: This is the middle level of 3-level data abstraction architecture. It describes what data is stored in database.
Example: Let’s say we are storing customer information in a customer table. At physical level these records can be described as blocks of storage (bytes, gigabytes, terabytes etc.) in memory. These details are often hidden from the programmers.
At the logical level these records can be described as fields and attributes along with their data types, their relationship among each other can be logically implemented. The programmers generally work at this level because they are aware of such things about database systems.
At view level, user just interact with system with the help of GUI and enter the details at the screen, they are not aware of how the data is stored and what data is stored; such details are hidden from them.
2.Instance and schema in DBMS
DBMS Schema
Definition of schema: Design of a database is called the schema. Schema is of three types: Physical schema, logical schema and view schema.
The design of a database at physical level is called physical schema, how the data stored in blocks of storage is described at this level.
Design of database at logical level is called logical schema, programmers and database administrators work at this level, at this level data can be described as certain types of data records gets stored in data structures, however the internal details such as implementation of data structure is hidden at this level (available at physical level).
Design of database at view level is called view schema. This generally describes end user interaction with database systems.
DBMS Database Models
A Database model defines the logical design and structure of a database and defines how data will be stored, accessed and updated in a database management system. While the Relational Model is the most widely used database model, there are other models too:
- Object based data model
- Entity-relationship Model
- object oriented model
- Relational Model
- Record based data model
- Hierarchical Model
- Network Model
a.Entity Relationship Data Model
Entity relationship model is based on the notion of the real world entities and their relationships. While formulating the real world scenario in to the database model an entity set is created and this model is dependent on two vital things and they are :
- Entity and their attributes
- Relationships among entities
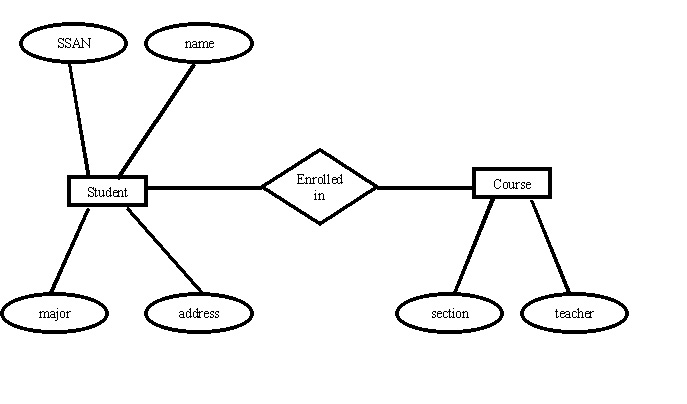
Entity Relationship Model
An entity has a real world property called attribute and attribute define by a set of values called domain. For example, in a university a student is an entity, university is the database, name and age and sex are the attributes. The relationships among entities define the logical association between entities.
b. Object oriented Data Model
Object oriented data model is one of the developed data model and this can hold the audio, video and graphic files. These consist of data piece and the methods which are the DBMS instructions.
c. Relational Model
The most common model, the relational model sorts data into tables, also known as relations, each of which consists of columns and rows. Each column lists an attribute of the entity in question, such as price, zip code, or birth date. Together, the attributes in a relation are called a domain. A particular attribute or combination of attributes is chosen as a primary key that can be referred to in other tables, when it’s called a foreign key.
Each row, also called a tuple, includes data about a specific instance of the entity in question, such as a particular employee.
The model also accounts for the types of relationships between those tables, including one-to-one, one-to-many, and many-to-many relationships. Here’s an example:

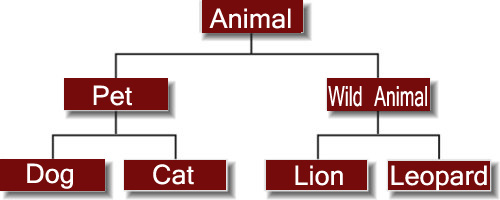
d.Hierarchical Data Model
Hierarchical model has one parent entity with several children entity but at the top we should have only one entity called root. For example, department is the parent entity called root and it has several children entities like students, professors and many more.
e.Network Model
This is an extension of the Hierarchical model. In this model data is organised more like a graph, and are allowed to have more than one parent node.
In this database model data is more related as more relationships are established in this database model. Also, as the data is more related, hence accessing the data is also easier and fast. This database model was used to map many-to-many data relationships.
This was the most widely used database model, before Relational Model was introduced.

