What Is Linked List? (2002 , 2007,2011)
Linked list is one in which all nodes are linked together .Each node contains two parts.
- Data contains elements .

- Next/Link contains address of next node .
Structure of singly linked list
- The head always points to the first node .
- All nodes are connected to each other through Link fields.
- Null pointer indicated end of the list.

Benefits of linked list over array( 2002,2007,2012)
Disadvantages of arrays :
- Insertion and deletion operations are slow.
- Slow searching in unordered array.
- Wastage of memory.
- Fixed size.
- More expensive
Linked lists solve some of these problems :
- Insertions and deletions are simple and faster.
- Linked List reduces the access time.
- No wastage of memory.
- Linked list is able to grow in size.
- Less expensive
Linked List Types (2012)
- Single Linked list
- Double linked list
- Circular single linked list
- Circular double linked list
-
Single Linked list

The basic operations on linked lists are :
- Insertion
- Deletion
- Searching
A)Insertion
Insertion operation is used to insert a new node in the linked list at the specified position. When the list itself is empty , the new node is inserted as a first node.
Types of Insertion
There are 3 ways to insert a new node into a list :
- Insertion at the beginning
- Insertion at the end
- Insertion after a particular node
Structure of Node of Single Linked List
/* Class Node */
class Node
{
int data;
Node next;
/* Constructor */
public Node()
{
next= null;
data = 0;
}
Algorithm
Step 1: Create a newNode with given value.
Step 2: Check whether list is Empty (head == NULL)
Step 3: If it is Empty then, set newNode→next = NULL and head = newNode.
Step 4: If it is Not Empty then, set newNode→next = head and head = newNode.
/* Function to insert an element at begining */ (2002)
public void insert()
{
Node newNode = new Node();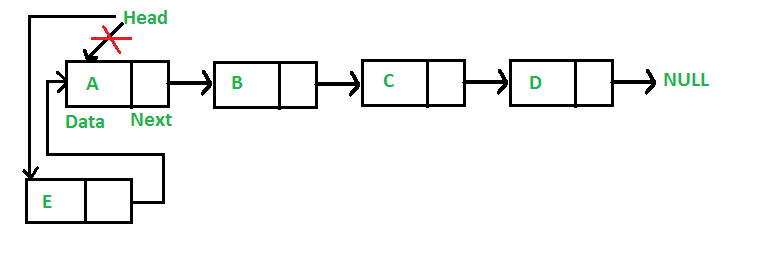
if (head == null)
{
newNode.next = null;
head = newNode;
tail = newNode;
} else {
newNode.next = head;
head = newNode;
}
}
}
/* Function to insert an element at end */
public void insert()
{
Node newNode = new Node();

if (head == null) {
head = newNode;
tail = newNode;
} else {
tail.next = newNode;
tail = newNode;
}
}
}
2.Deletion
Deletion operation is used to delete a particular node in the linked list. we simply have to perform operation on the link of the nodes(which contains the address of the next node) to delete a particular element.
Types of Deletion
Deletion operation may be performed in the following conditions:
- Delete first element.
- Delete last element.
- Delete a particular element
Delete first element.
Algorithm
Step 1: Check whether list is Empty (head == NULL)
Step 2: If it is Empty then, display ‘List is Empty!!! Deletion is not possible’ and terminate the function.
Step 3: If it is Not Empty then, define a Node pointer ‘temp’ and initialize with head.
Step 4: Check whether list is having only one node (temp → next == NULL)
Step 5: If it is TRUE then set head = NULL and delete temp (Setting Empty list conditions)
Step 6: If it is FALSE then set head = temp → next, and delete temp.
/* Function to delete an element from first */ (2002)
public void removeFirst() {
if (head == null)
return;
else {
if (head == tail) {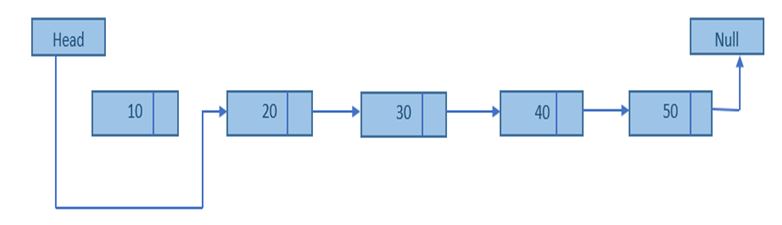
head = null;
tail = null;
} else {
head = head.next;
}
}
}
Deleting the last node of a singly linked list (2007)
public void removeLast()
{
if (tail == null)
return;
else {
if (head == tail) {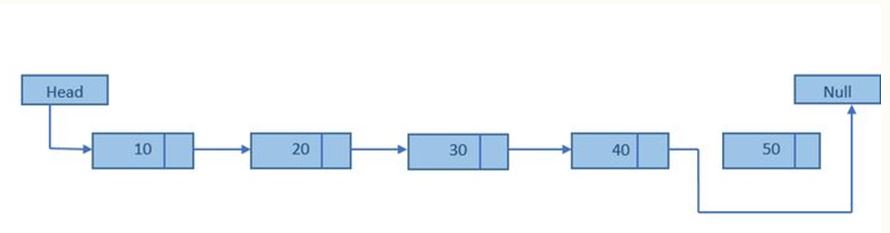
head = null;
tail = null;
}
else {
Node prev = head;
while (previ.next != tail)
{
prev = prev.next;
}
tail = prev;
tail.next = null;
}
}
}
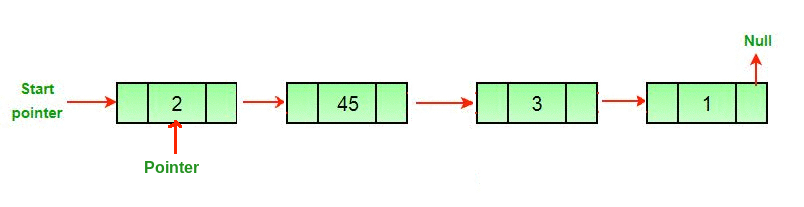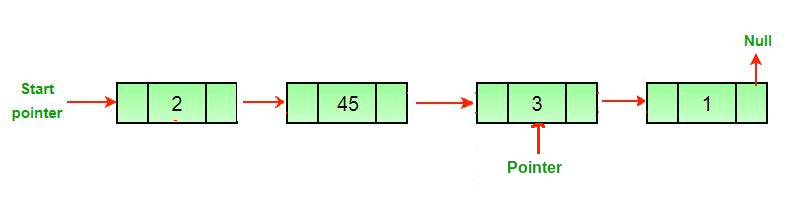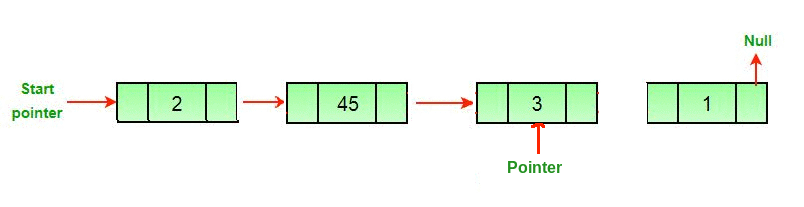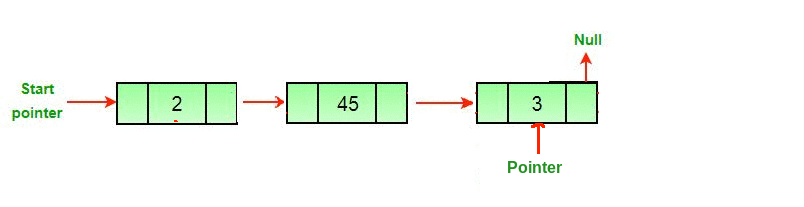
3. Searching
Searching involves finding the required element in the list.We can use various techniques of searching like linear search or binary search where binary search is more efficient in case of Arrays.But in case of linked list since random access is not available it would become complex to do binary search in it.We can perform simple linear search traversal.
Function
class LinkedList{
Node head; //Head of list
public void push(int new_data {
Node new_node = new Node(new_data);
new_node.next = head;
head = new_node;
}
//Checks whether the value x is present in linked list
public boolean search(Node head, int x)
{
Node current = head; //Initialize current
while (current != null)
{
if (current.data == x)
return true; //data found
current = current.next;
}
return false; //data not found
}
2. Circular linked list

A circular linked list is one which has
- No ending.
- The last node of a linked list is connected with the address of its first node .
In the circular linked list we can insert elements anywhere in the list whereas in the array we cannot insert element anywhere in the list because it is in the contiguous memory.
/* Function to insert element at begining In Circular linked list*/
public void insert(int val) {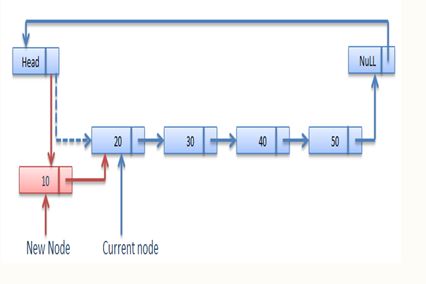
Node newNode= new Node();
if(start == null)
{
newNode.next=newNode
head = newNode;
tail = newNode;
}
else {
head.next=head
last.next = newNode;
head = newNode; }
size++ ;
}
/* Function to insert element at end In Circular linked list*/
public void insert()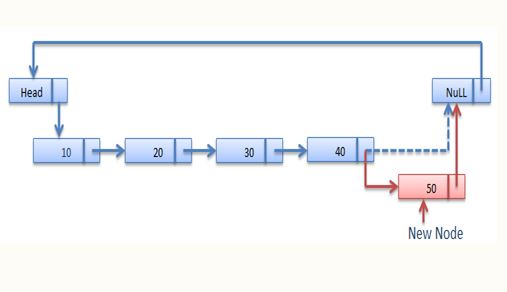
{
Node newNode= new Node();
if(start == null)
{
head=tail= newNode;
newNode.next=newNode;
}
else
{
last= newNode;
last.next=newNode
newnode.next=head;
}
}
/* Function to insert element at position in circular linked list */
public void insertAtPos(int val , int pos)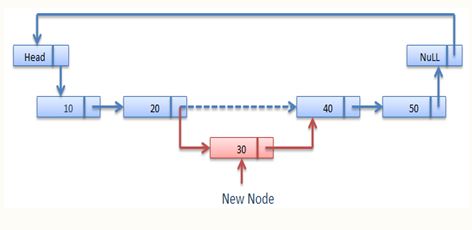
{
Node newNode= new Node(val,null);
Node ptr = start;
pos = pos – 1 ;
for (int i = 1; i < size – 1; i++)
{
if (i == pos)
{
Node tmp = ptr.getLink() ;
ptr.setLink( newNode);
newNode.setLink(tmp);
break;
}
ptr = ptr.getLink();
}
size++ ;
}
Deletion at beginning in the Circular linked list
public void deletet()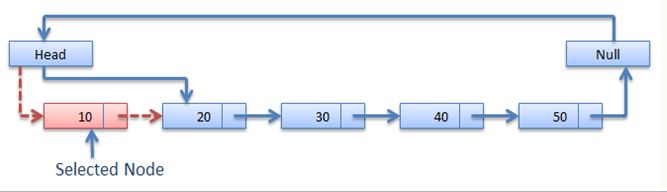
{
if(size==0){
System.out.println(“\nList is Empty”);
}else{
System.out.println(“\ndeleting node ” + head.data + ” from start”);
head = head.next;
tail.next=head;
size–;
}
}
3. Doubly Linked List

1. Doubly linked list is a linked data structure that consists of a set of sequentially linked records called nodes. Each node contains three fields :
-: one is data part which contain data only.
-:two other field is links part that are point or references to the previous or to the next node in the sequence of nodes.
The beginning and ending nodes’ previous and next links respectively, point to some kind of terminator ,typically a sentinel node or null to facilitate traversal of the list.Hence each node has knowledge of its successor and also its predecessor. In doubly linked list, from every node the list can be traversed in both the directions.
DLL’s compared to SLL’s
Advantages:
- Can be traversed in either direction (may be essential for some programs)
- Some operations, such as deletion and inserting before a node, become easier
Disadvantages:
- Requires more space
- List manipulations are slower (because more links must be changed)
- Greater chance of having bugs (because more links must be manipulated)
Let’s see how the Node structure will look like
class Node
{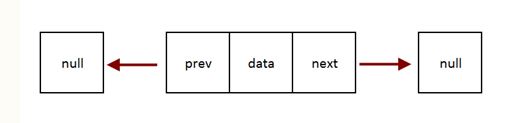
int data;
Node next, prev;
//constructs a new DoublyLinkedList object with head and tail as null
public Node()
{
next = null;
prev = null;
data = 0;
}
Insertion at the beginning of doubly linked list (2009)
public Node addAtStart(int data){
System.out.println(“Adding Node ” + data + ” at the start”);
Node newnode = new Node(data);
if(head=null)
{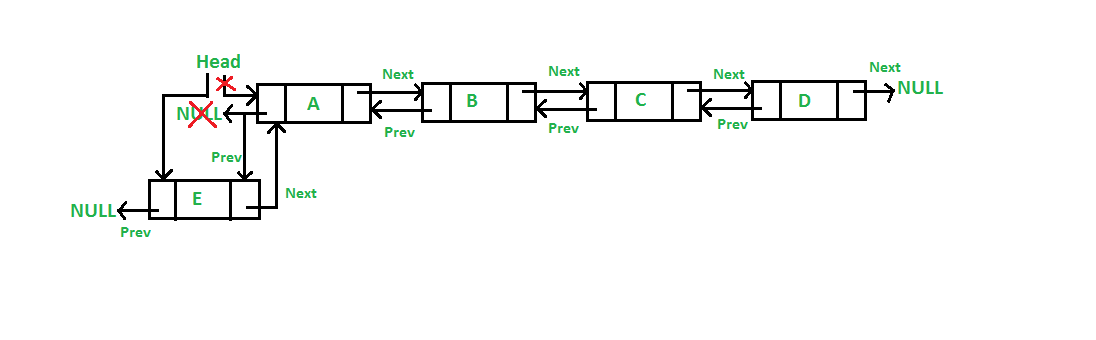
head = newnode;
tail = newnode;
}
else
{
/*Make next of new node as head and previous as NULL */
newnode.next = head;
head.previous = newnode;
head = newnode;
}
size++;
return n;
}
Insertion at last of doubly linked list
public Node addAtEnd(int data)
{
System.out.println(“Adding Node ” + data + ” at the End”);
Node newNode= new Node(data);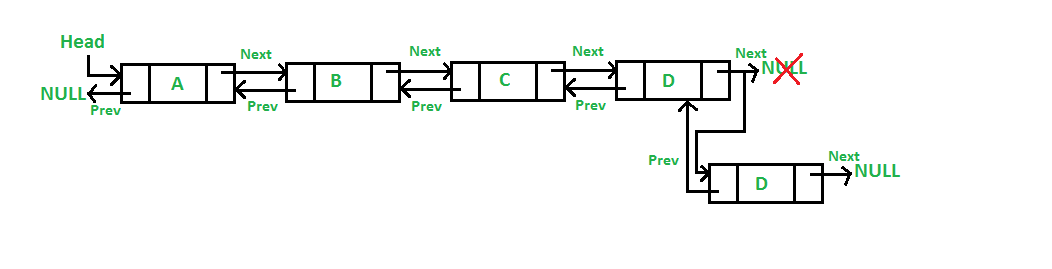
if(head = =null{
head = newNode;
tail = newNode;
}else{
tail.next = newNode; /*Change the next of last/tail node */
newNode.previous = tail; /*Make last node as previous of new node */
tail =newNode;
}
size++;
return n;
}
Deletion at the beginning of doubly linked list (2012)
public void delete()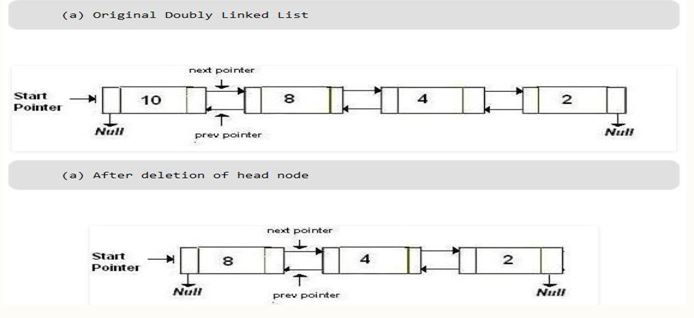
{
if(head==null)
{
System.out.println(“\nList is Empty”);
}
Else if(head==tail)
{
head=tail=null;
}
else{
System.out.println(“\ndeleting node ” + head.data + ” from start”);
head = head.next;
size–;
}
}
Deletion frome end of doubly linked list
public void print()
{
Node temp = head;
System.out.print(“Doubly Linked List: “);
while(temp!=null){
System.out.print(” ” + temp.data);
temp = temp.next;
}
System.out.println();
}
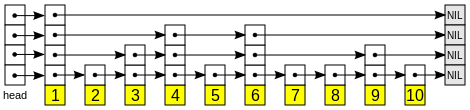
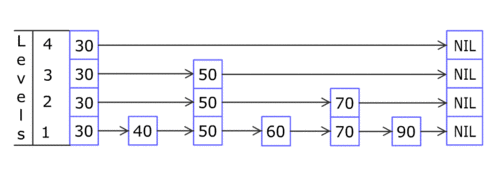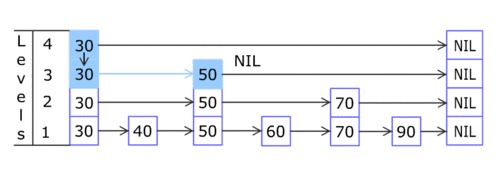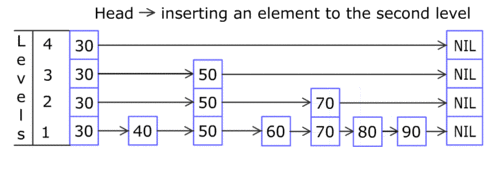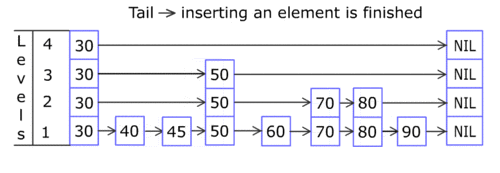
Skip List
A skip list is a data structure that is used for storing a sorted list of items with a help of hierarchy of linked lists that connect increasingly sparse subsequences of the items. A skip list allows the process of item look up in efficient manner. The skip list data structure skips over many of the items of the full list in one step, that’s why it is known as skip list.
Complexity |
Average Case | Worst Case |
| Space | O(n) | O(nlogn) |
| Search | O(logn) | O(n) |
| Insert | O(logn) | O(n) |
| Delete | O(logn) | O(n) |
Structure of Skip List
A skip list is built up of layers. The lowest layer (i.e. bottom layer) is an ordinary ordered linked list. The higher layers are like ‘express lane’ where the nodes are skipped (observe the figure).
Searching Process
When an element is tried to search, the search begins at the head element of the top list. It proceeds horizontally until the current element is greater than or equal to the target. If current element and target are matched, it means they are equal and search gets finished.If the current element is greater than target, the search goes on and reaches to the end of the linked list, the procedure is repeated after returning to the previous element and the search reaches to the next lower list (vertically).
Implementation Details
- The elements used for a skip list can contain more than one pointers since they are allowed to participated in more than one list.
- Insertion and deletion operations are very similar to corresponding linked list operations.
Applications of Skip List
- Skip list are used in distributed applications. In distributed systems, the nodes of skip list represents the computer systems and pointers represent network connection.
- Skip list are used for implementing highly scalable concurrent priority queues with less lock contention (struggle for having a lock on a data item).
SELF ORGANIZING LIST
A self-organizing list is a list that reorders its elements based on some self-organizing heuristic to improve average access time.The aim of a self-organizing list is to improve efficiency of linear search by moving more frequently accessed items towards the head of the list.The simplest implementation of self-organizing list is as a linked list.A self-organizing list achieves near constant time for element access in the best case.A self-organizing list uses a reorganizing algorithm to adapt to various query distributions at runtime.
DIFFERENT TYPES OF TECHNIQUES TO ORGANIZE LISTS
––MOVE TO FRONT(MTF)
–TRANSPOSE
–COUNT
–ORDERING
MOVE TO FRONT(MTF)
This technique moves the element which is accessed to the head of the list.This has the advantage of being easily implemented and requiring no extra memory.–This heuristic also adapts quickly to rapid changes in the query distribution.

B) TRANSPOSE
This technique involves swapping an accessed node with its predecessor.Therefore, if any node is accessed, it is swapped with the node in front unless it is the head node, thereby increasing its priority.This algorithm is again easy to implement and space efficient and is more likely to keep frequently accessed nodes at the front of the list.

C) COUNT
In this technique, the number of times each node was searched for is counted i.e. every node keeps a separate counter variable which is incremented every time it is called.The nodes are then rearranged according to decreasing count.Thus, the nodes of highest count i.e. most frequently accessed are kept at the head of the list.

ORDERING TECHNIQUE
This technique orders a list with a particular criterion.For e.g in a list with nodes 2,3,7,10.If we want to access node 5, then the accessed node is added between 3 and 7 to maintain the order of the list i.e. increasing order.
In the first three techniques i.e. move to front, transpose and count ,node is added at the end whereas in the ordering technique , node is added somewhere to maintain the order of the list.
APPLICATIONS of Self Organizing List
- Language translators like compilers and interpreters use self-organizing lists to maintain symbol tables during compilation or interpretation of program source code.
- Currently research is underway to incorporate the self-organizing list data structure in embedded systems to reduce bus transition activity which leads to power dissipation in some circuits.
- These lists are also used in artificial intelligence and neural networks as well as self-adjusting programs.
- The algorithms used in self-organizing lists are also used as caching algorithms as in the case of LFU algorithm.
Sparse Tables
Sparse table stores the information from one index ‘i’ to some index ‘j’ which is at a specific distance from ‘i’.Suppose our query is regarding minimum element in range (L,R) or Range Minimum Query (RMQ) on a given array.Sparse Table uses dynamic programming to store the index of minimum element in any range (i,j) .We can use Sparse table to store the minimum of the elements between index ‘i’ to i+’2^j’.
Build a Sparse Table on array 3 1 5 3 4 7 6 1

