Defination
A transaction is the basic logical unit of execution in an information system.
A transaction is an event which occurs on the database. Generally a transaction reads a value from the database or writes values to the database.
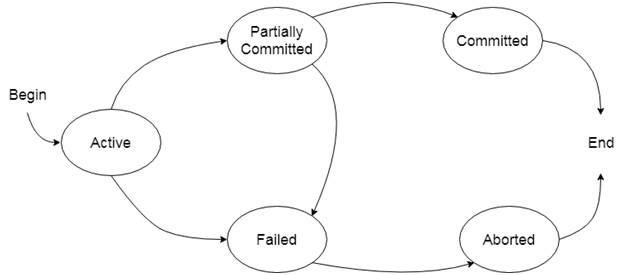
State of Transaction
Active :A transaction enters into an active state when the execution process begins. During this state read or write operations can be performed.
Partially committed:A transaction goes into the partially committed state after the end of a transaction.
Failed:If the transaction fails for some reason, the temporary values are no longer required and the transaction set to roll back.
Aborted:When the rollback operation is over,the database reaches the BFIM. The transaction is said to have been aborted.
Committed:If no failure occurs then the transaction reaches the commit point.All the temporary values are written to stable storage and the transaction is said to be committed.
Terminated:Either committed or aborted transaction finally reach this state.
Process of Transaction
The transaction is executed as a series of reads and writes of database objects, which are explained below:
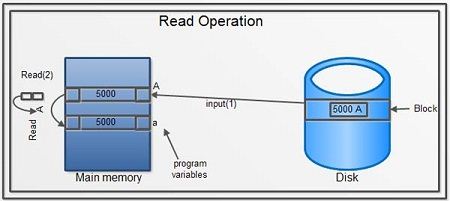
Read Operation
To read a database object, it is first brought into main memory from disk, and then its value is copied into a program variable as shown in figure.
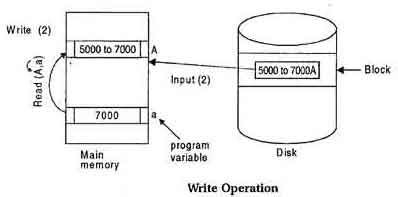
Write Operation
To write a database object, an in-memory copy of the object is first modified and then written to disk.
ACID Properties in DBMS
A transaction is a single logical unit of work which accesses and possibly modifies the contents of a database. Transactions access data using read and write operations.
In order to maintain consistency in a database, before and after transaction, certain properties are followed. These are called ACID properties.
Atomicity (all or nothing)
By this, we mean that either the entire transaction takes place at once or doesn’t happen at all. There is no midway i.e. transactions do not occur partially. Each transaction is considered as one unit and either runs to completion or is not executed at all. It involves following two operations.
—Abort: If a transaction aborts, changes made to database are not visible.
—Commit: If a transaction commits, changes made are visible.
Atomicity is also known as the ‘All or nothing rule’.
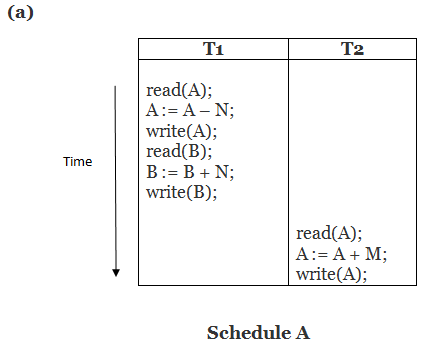
Consider the following transaction T consisting of T1 and T2: Transfer of 100 from account X to account Y.
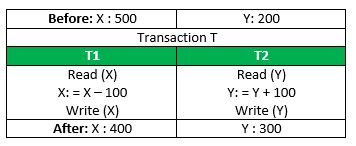
If the transaction fails after completion of T1 but before completion of T2.( say, after write(X) but before write(Y)), then amount has been deducted from X but not added to Y. This results in an inconsistent database state. Therefore, the transaction must be executed in entirety in order to ensure correctness of database state.
Consistency (No violation of integrity constraints)
This means that integrity constraints must be maintained so that the database is consistent before and after the transaction. It refers to correctness of a database. Referring to the example above,
The total amount before and after the transaction must be maintained.
Total before T occurs = 500 + 200 = 700.
Total after T occurs = 400 + 300 = 700.
Therefore, database is consistent. Inconsistency occurs in case T1 completes but T2 fails. As a result T is incomplete.
Isolation (concurrent changes invisibles)
This property ensures that multiple transactions can occur concurrently without leading to inconsistency of database state. Transactions occur independently without interference. Changes occurring in a particular transaction will not be visible to any other transaction until that particular change in that transaction is written to memory or has been committed. This property ensures that the execution of transactions concurrently will result in a state that is equivalent to a state achieved these were executed serially in some order.
Let X= 500, Y = 500.
Consider two transactions T and T”.

Suppose T has been executed till Read (Y) and then T’’ starts. As a result , interleaving of operations takes place due to which T’’ reads correct value of Xbut incorrect value of Y and sum computed by
T’’: (X+Y = 50, 000+500=50, 500)
is thus not consistent with the sum at end of transaction:
T: (X+Y = 50, 000 + 450 = 50, 450).
This results in database inconsistency, due to a loss of 50 units. Hence, transactions must take place in isolation and changes should be visible only after a they have been made to the main memory.
Durability:(committed update persist)
This property ensures that once the transaction has completed execution, the updates and modifications to the database are stored in and written to disk and they persist even if system failure occurs. These updates now become permanent and are stored in a non-volatile memory. The effects of the transaction, thus, are never lost.
The ACID properties, in totality, provide a mechanism to ensure correctness and consistency of a database in a way such that each transaction is a group of operations that acts a single unit, produces consistent results, acts in isolation from other operations and updates that it makes are durably stored.
Atomicity, Durability and Serializability
Atomicity: This means that either all of the instructions within the transaction will be reflected or none of them will be reflected.
Durability:It states that once the transaction has completed the change, it should be permanent.
Serializability:The serializability of schedules is used to find non-serial schedules that allow the transaction to execute concurrently without interfering with one another.It identifies which schedules are correct when executions of the transaction have interleaving of their operations.
Concurrent execution
A schedule is a collection of many transaction which is implemented as a unit. Depending upon how a transaction are arranged within a schedule, schedule is of two types:
Serial schedule: The transaction are executed one after another, in non-preemptive manner.
Concurrent schedule: The transaction are executed in a preemptive , time shared method.
The process of managing simultaneous operations on the database without having them interfere with each other. The coordination of the simultaneous execution of transactions in a multiprocessing database is known as concurrency control The objective of concurrency control is to ensure the serializability of transactions in a multiuser database environment.
Concurrency control is the problem of synchronizing concurrent transactions (i.e.,order the operations of concurrent transactions) such that the following two properties are achieved:
– the consistency of the DB is maintained
– the maximum degree of concurrency of operations is achieved
when multiple transaction try to access same sharable resources there could be many problems if the access is not done properly. There are some important mechanism to which access control can be maintained.They are lock and timestamp protocols.
Lock based protocols
A lock is nothing but a mechanism that tells the DBMS whether a particular data item is being used by any transaction for read , write purpose.
The simple rule for locking can be derived from here if a transaction is reading a content of shareable data items then any number of other process can be allowed to read the content of same data item. But if any transaction is writing into sharable data item then no other transaction will be allowed to read or write the same data item.
Depending upon the rules ,we have found we can classify the locks into two types:
- Sharable lock( lock-s): A transaction may acquire shared lock on same data item in order to read its content the lock is shared in sense that any other transaction can acquire the shared lock on that same data item for reading purpose.
- Exclusive lock( lock-x): A transaction may acquire exclusive lock on a data item in order to both read/ write into it. The lock is exclusive in the sense that no other transaction can acquire any kind of lock (either shared or exclusive) on the same data item.
How should lock be used?
In a transaction the data item that we want to read/write should first be locked before the read/write is done. After operation is over, the transaction should then unlock the data item so other transaction can lock the data item for their respective usage. The transaction should now be written as the following:
lock-x(A) //exclusive lock,we want to both read A’s value and modify it
Read A;
A=a-100;
write A;
unlock A //unlocking A after modification
lock-x(B);//exclusive lock, we want to both read B’s value and modify it
Read B;
B=B+100;
write B;
unlock B;
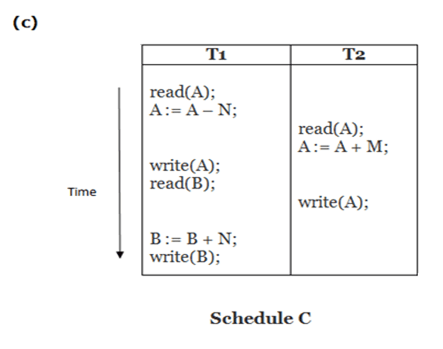
Let’s see how these locking mechanism help us to create error free schedule
T1 T2
Locking protocol:
Two phase locking protocol:-
The use of lock has helped us to create neat and clean concurrent schedule. This is a protocol which ensures conflict-serializable schedules. This protocol requires that each transaction issue lock and unlock requests in different phases. There are two phases as discussed below:
Phase 1: Growing Phase
• transaction may obtain locks
• transaction may not release locks
Phase 2: Shrinking Phase
• transaction may release locks
• transaction may not obtain locks
For example: Transaction T20 and T30 are the example of two phase locking protocol. Initially a transaction is in growing phase and can acquire locks as per its need. Then the transaction reaches its lock point i.e. it is the point where a transaction acquires its final lock. Finally when transaction unlocks any data item, it enters into shrinking phase and no more locks can be acquired again.
The protocol assures serializability. It can be proved that the transactions can be serialized in the order of their lock points (i.e. the point where a transaction acquired its final lock). Two-phase locking does not ensure freedom from deadlocks.
Cascading roll-back is possible under two-phase locking. To avoid this, follow a modified protocol called strict two-phase locking. Here a transaction must hold all its exclusive locks till it commits/aborts. Rigorous two-phase locking is even stricter: here all locks are held till commit/abort. In this protocol transactions can be serialized in the order in which they commit.
Lock conversion: Two-phase locking with lock conversions:
– Growing Phase:
• can acquire a lock-S on item
• can acquire a lock-X on item
• can convert a lock-S to a lock-X (upgrade)
Time Stamp Based Protocol
 Problem with timestamp-ordering protocol:
Problem with timestamp-ordering protocol: