Hashing is an approach to searching, which calculates the position of the key in the table based on the value of the key.It is an efficient technique in which key is placed in direct accessible address for rapid search.When the key is known, the position in the table can be accessed directly, without making any other tests.In hashing, the search time is O(n)
Hash Function
Hash function is a function which is used to compute the address of a record in the hash table .It is a function that can transform a particular key (be it a string, number, record, etc), into an index in the table used for storing items of the same type as K. If h transforms different keys into different numbers, it is called a perfect hash function.To create a perfect hash function, the table has to contain at least the same number of positions as the number of elements being hashed.
Types of Hash Function
i.Division
ii.Folding :- a)Shift Folding b)Boundary Folding
iii.Mid Square Function
iv. Extraction
i. Division
It is the simplest hash function.If there are m slots available, then the key is mapped to given m slots using following formula:-
h(k) = k mod m
For example:- Let us say apply division approach to find hash value for some values considering number of buckets be 10 as shown below.

The division method is generally a good choice, unless the key happens to have some undesirable properties. For example, if the table size is 10 and all of the keys end in zero. In this case, the choice of hash function and table size needs to be carefully considered. The best table sizes are prime numbers.
ii. Folding
In this method, the key is divided into several parts (which conveys the true meaning of the word hash).These parts are combined or folded together and are often transformed in a certain way to create the target address.The key is divided into several parts and these parts are then processed using a simple operation such as addition to combine them in a certain way.There are two types of folding:
a)Shift folding
b)Boundary folding
a)Shift Folding
In shift folding, they are put underneath one another and then processed.For example, a social security number (SSN) 123-45-6789 can be divided into three parts, 123, 456, 789, and then these parts can be added.The resulting number, 1,368, can be divided modulo TSize or, if the size of the table is 1,000, the first three digits can be used for the address
b)Boundary Folding
With boundary folding, the key is seen as being written on a piece of paper that is folded on the borders between different parts of the key.In this way, every other part will be put in the reverse order.Consider the same three parts of the SSN: 123, 456, and 789
The first part, 123, is taken in the same order, then the piece of paper with the second part is folded underneath it so that 123 is aligned with 654, which is the second part, 456, in reverse order.When the folding continues, 789 is aligned with the two previous parts. The result is 123 + 654 + 789 = 1,566
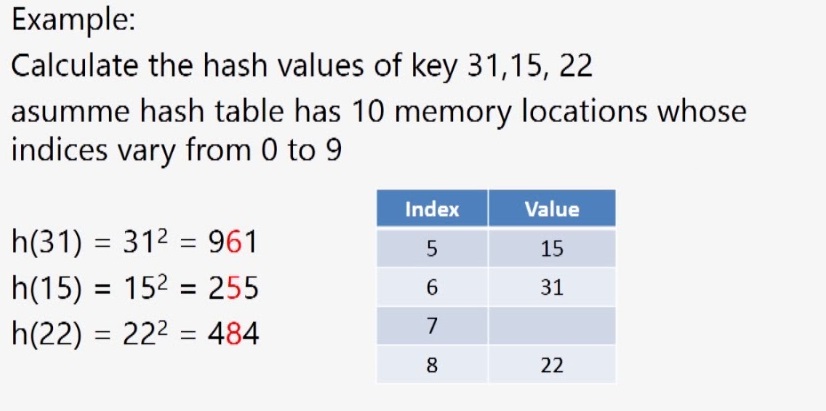
iii. Mid-Square Function
In the mid-square method, the key is squared and the middle or mid part of the result is used as the address.In a mid-square hash function, the entire key participates, in generating the address so that there is a better chance that different addresses are generated for different keys.
Collision
It is a situation where two different keys hash to the same value, i.e. to the same location in a hash table.In a division method, collision occurs in a table with table size 10, when we try to insert 19 and 29(19 mod 10= 9 and 29 mod 10=
Collision Resolution
Collision resolution is the mechanism of solving the problem of collision.Collision leads the hash table to an inconsistent state.Thus, it is very important that the elements are properly arranged in case of collision.Collision can be reduced by increasing the size of the table and using efficient hashed keys, but can never be completely avoided
We have the following techniques for resolving the collision:
- Chaining
- Bucket Addressing
- Open Addressing
Chaining
In chaining, each position of the table is associated with a linked list or chain of structures whose info fields store keys or references to keys.This method is called separate chaining, and a table of references (pointers) is called a scatter table.In this method, the table can never overflow, because the linked lists are extended only upon the arrival of new keys.However, increasing the length of these lists can significantly degrade retrieval performance.
This method requires additional space for maintaining references.The table stores only references, and each node requires one reference field.Therefore, for n keys, n + TSize references are needed, which for large n can be a very demanding requirement
Coalesced hashing/ Coalesced chaining
It combines linear probing with chaining.In this method, the first available position is found for a key colliding with another key, and the index of this position is stored with the key already in the table.In this way, a sequential search own the table can be avoided by directly accessing the next element on the linked list.Each position pos of the table includes two fields:
- an info field for a key and
- a next field with the index of the next key that is hashed to pos.
Bucket Addressing
The colliding items can also be stored in an overflow area.In this case, each bucket includes a field that indicates whether the search should be continued in this area or not.It can be simply a yes/no marker.In conjunction with chaining, this marker can be the number indicating the position in which the beginning of the linked list associated with this bucket can be found in the overflow area
Open Addressing
In the open addressing method, when a key collides with another key, the collision is resolved by finding an available table entry other than the position (address) to which the colliding key is originally hashed.If position h(K) is occupied, then the positions in the probing sequence norm(h(K) + p(1)), norm(h(K) + p(2)), . . . , norm(h(K) + p(i)), . . . are tried until either an available cell is found or the same positions are tried repeatedly or the table is full.Function p is a probing function, i is a probe, and norm is a normalization function, most likely, division modulo the size of the table
Types of Open Addressing
- Linear Probing
- Quadratic Probing
- Double Hashing
Linear Probing
In linear probing, the position in which a key can be stored is found by sequentially searching all positions starting from the position calculated by the hash function until an empty cell is found.If the end of the table is reached and no empty cell has been found, the search is continued from the beginning of the table and stops (in the extreme case, in the cell preceding the one from which the search started).The position is derived as p(i) = i, and for the ith probe, the position to be tried is (h(K) + i) mod TSize. the major drawback is linear probing is it create clusters. Once the cluster is created, it keeps on growing.
Quadratic Probing
It uses the following formula for solving the problem:
uh(K) + i2, h(K) – i2 for i = 1, 2, . . . , (TSize – 1)/2
The size of the table should not be an even number, because only the even positions or only the odd positions are tried depending on the value of h(K).Ideally, the table size should be a prime 4j + 3 of an integer j, which guarantees the inclusion of all positions in the probing sequence
Double Hashing
The problem of secondary clustering is best addressed with double hashing.This method utilizes two hash functions, one for accessing the primary position of a key, h, and a second function, hp, for resolving conflicts.Like linear probing, it uses one hash value as a starting point and then repeatedly steps forward an interval until the desired value is located, an empty location is reached, or the entire table has been searched; but this interval is decided using a second, independent hash function